
Artículo de Alejandro Municio, Lead Data Scientist en PiperLab.
Recientemente, tuve la oportunidad de impartir una ponencia en uno de los foros del CEL. Como experto en Inteligencia Artificial aplicada a negocio, mi ponencia consistió en explicar cómo se podían aplicar diversas técnicas para trabajar en entornos VUCA relacionados con la logística, ilustrando cada idea con aplicaciones prácticas que hemos realizado desde Piperlab en el marco de diferentes proyectos.

A continuación, tras finalizar mi ponencia, pude asistir a otra charla que trataba sobre DDMRP como metodología de planificación avanzada de la cadena de suministro. Esta charla despertó en mi una gran curiosidad, puesto que desconocía esta metodología,
Desde mi entendimiento, existen dos maneras de planificar la producción:
- De forma eficiente, utilizando un modelo de predicción de demanda que sea lo más precisa posible, y utilizando, entre otros factores, su nivel de incertidumbre para dimensionar el stock de seguridad.
- De forma menos eficiente, renunciando a utilizar una predicción precisa, pero incurriendo en un sobredimensionamiento de los stocks de seguridad.
Sin embargo, en la ponencia se exponía que gracias a la metodología DDMRP, se puede planificar de forma eficiente mediante un concepto llamado “buffer”, que reemplaza al stock de seguridad, y no necesita de predicciones futuras de la demanda.
Así pues, me decidí a leer y documentarme para aprender más sobre la metodología DDMRP, que daba lugar a esta idea tan interesante. Para ello utilicé como principal referencia el libro “Demand Driven Material Requirements Planning (DDMRP)”, escrito por Carol Ptak y Chad Smith, que se recomendó durante la misma ponencia. Durante este proceso pude analizar y profundizar sobre la metodología DDMRP, y, para mi gran sorpresa, llegué a la siguiente conclusión:
Una buena predicción de la demanda es la mejor amiga de la metodología DDMRP.
¿En qué consisten los buffers?
En la metodología DDMRP, un buffer es una reserva de inventario que se coloca en ciertos puntos clave en la cadena de suministro para evitar que los cambios inesperados en la demanda o el suministro afecten la producción y la entrega de los productos. Por ejemplo, se pueden colocar buffers en los puntos de distribución y en los puntos de producción para asegurar que haya suficiente inventario disponible en caso de que surjan problemas en la cadena de suministro.
Cada buffer tiene tres zonas, representadas por los colores verde, amarillo y rojo. Estas zonas sirven para generar y priorizar las órdenes sobre la cadena de suministro. Por ejemplo, si el nivel de inventario del buffer se encuentra en un punto inferior a la zona verde, se generará una orden para volverlo a llenar.
Las tres zonas del buffer se dimensionan dinámicamente utilizando las fórmulas mostradas en la siguiente imagen:
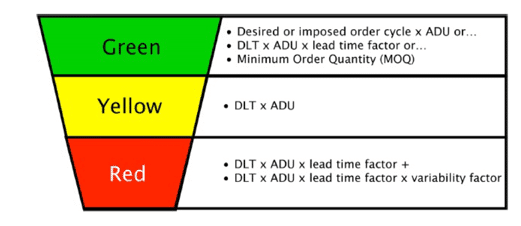
Las fórmulas de dimensionamiento del buffer contienen dos métricas fundamentales, que se utilizan en las tres zonas:
- Average Daily Use (ADU): Cantidad promedio de una determinada materia prima o producto que se utiliza diariamente.
- Decoupled Lead Time (DLT): El mayor de tiempo de entrega, de forma acoplada y acumulativa, en la estructura del producto fabricado. Es una forma de tiempo de entrega acumulativo, pero está limitado y definido por la colocación de puntos de desacoplamiento dentro de una estructura de producto.
De estas dos métricas principales, el ADU está directamente relacionado con la demanda sobre el producto final, y condiciona directamente el dimensionamiento de los niveles de stock a mantener.
Average Daily Use (ADU)
Como hemos visto anteriormente, el ADU se calcula como un promedio de utilización diaria de un producto o material. Este promedio se calcula sobre una determinada ventana de tiempo.
Sobre el cálculo del ADU, la metodología DDMRP explica que hay que tomar algunas decisiones, aunque en muchos casos no se proporciona un método claro y objetivo para hacerlo. En entre estas decisiones están las siguientes:
- Dimensionamiento de la ventana temporal para calcular del ADU (Length-of-Period)
- Frecuencia de actualización del ADU
- Definición de excepciones y alertas para variaciones agresivas
- Elección del ADU para ítems sin histórico de demanda
- Manipulación del ADU mediante factores de ajuste (DAF)
- Utilización de demanda pasada, futura o mixta para el cálculo del ADU
En este último punto, al utilizar valores futuros de demanda para calcular el ADU, se deja la puerta abierta a utilizar una predicción de demanda, aunque no se especifica como elaborarla. Adicionalmente, aunque el ADU en su cálculo solo empleara datos de demanda pasada, realmente trata de estimar la demanda futura en base a este dato, o lo que es lo mismo: ¡Se trata un modelo de predicción de demanda! De hecho, es uno de los modelos más simples que existen dentro del campo del análisis de series temporales, y tiene un nombre específico: modelo de media móvil o moving-average (MA).
El problema fundamental que tiene un modelo de predicción tan simple como el ADU, es que su precisión es muy limitada, lo que provoca un dimensionamiento de niveles de stock más altos de lo necesario. Para intentar paliar esto, requiere de calibraciones manuales sobre su cálculo y de la aplicación, también manual, de diferentes ajustes.
¿Qué podemos hacer para mejorar el ADU?
Sustituyamos el ADU por una previsión de demanda, generada por un modelo predictivo avanzado, entrenado a partir de datos históricos mediante aprendizaje automático (machine learning). Estos modelos son el estado del arte actual en cuanto a predicción de series temporales, y son capaces de considerar patrones notoriamente más complejos, por ejemplo: estacionalidades múltiples, variaciones de tendencia, variables adicionales a la demanda, interacciones entre las diferentes variables, etc.
Al hacer esto, se pueden obtener las siguientes mejoras:
- Reducción considerable del error en la estimación de demanda futura.
- Disminución del almacenaje requerido, manteniendo el mismo nivel de servicio.
- Capacidad de incorporar y tratar de una forma robusta diferentes variables exógenas (p. ej. meteorología o calendario) y variables conocidas por negocio (p. ej. aplicación de promociones).
- Al aplicar técnicas de selección de variables y de calibración del modelo mediante validación cruzada, se reduce la carga de trabajo y los riesgos asociados a la toma de decisiones arbitrarias y a la aplicación manual de factores de corrección.
Conclusiones
La metodología DDMRP establece una serie de técnicas y fundamentos muy prácticos e interesantes para la planificación avanzada de la cadena de suministro. No obstante, no es del todo perfecta, y tiene puntos clave para su mejora, como el que se ha analizado en este artículo, en los que otros campos tecnológicos y de conocimiento como la Inteligencia Artificial pueden aportar mucha luz.
Mi principal conclusión tras este análisis es que el discurso comercial más común de DDMRP debería pivotar, pasando de la negación de la planificación predictiva, a abrazarla e incorporarla adecuadamente dentro de la propia metodología ya que supone una gran fuente de valor. En los tiempos actuales la tecnología avanza a pasos de gigante, y aquellas áreas que no se actualizan adecuadamente corren el riesgo de quedar obsoletas.

")











