
La nueva biblioteca te permite predecir si se utilizó un dato específico durante el entrenamiento.
En 2019, TensorFlow añadió TensorFlow Privacy para gestionar la privacidad dentro de los modelos de IA. Ahora añade una nueva biblioteca de pruebas de privacidad que permitirá a los desarrolladores analizar las propiedades de privacidad de los modelos de clasificación.
La privacidad es un aspecto primordial actualmente, controlar y gestionar los datos que se manejan para entrenar un sistema de Inteligencia Artificial es importante, sobre todo para evitar que haya fugas de información. Google hace un tiempo ya integró la privacidad diferencial, esto permite añadir ruido al conjunto de datos de entrenamiento y así ocultar ejemplos individuales. Pero, con este sistema no se terminó de obtener los resultados deseados.
Ataque de inferencia de membresia con TensorFlow
Este nuevo sistema ha sido desarrollado por la Universidad de Cornell, y ahora Google ha decidido añadirlo como una nueva biblioteca a TensorFlow Privacy. Esta nueva metodología predice si se utilizó un dato específico durante el entrenamiento.
La Universidad de Edimburgo y el Instituto Alan Turing se inspiraron en el ataque de inferencia de membresia para saber si un modelo puede olvidar los datos para garantizar la privadad.
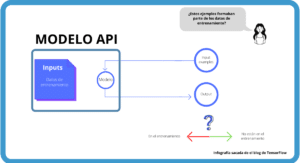
Una de las mayores ventajas de este sistema es que no es necesario el re-entrenamiento.
Prubea de funcionamiento
Para saber si realmente este sistema de privacidad daba buenos resultados se realizó una prueba con el modelo de CIFRA10, un conjunto de datos de clasificación de objetos.
Los resultados de la prueba son los que aparecen en la siguiente gráfica.
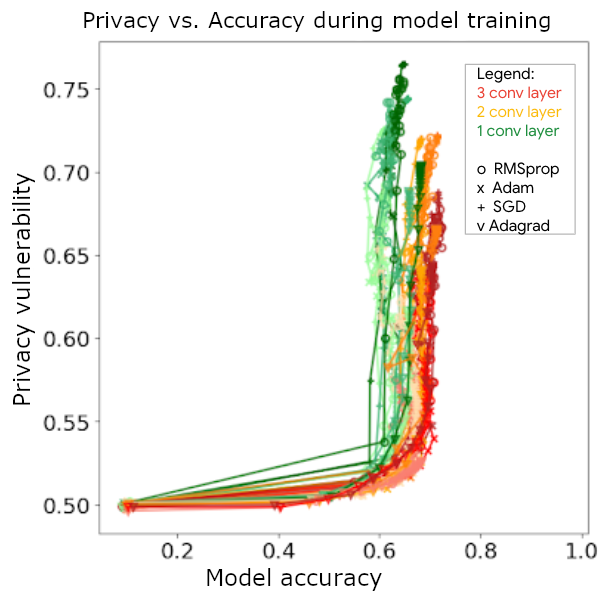

")











