
Artículo de Gerardo Raído, Chief Digital Officer de Data Centric.

La mayor parte de las soluciones de datos fracasan y esto se debe a diversos factores, y el más común es basarlo todo en la contratación de una determinada tecnología. En realidad, ni una herramienta Big Data ni ninguna algoritmia van a resolver problemas mágicamente o se van a poder implementar en digamos un modelo “plug & go”. Requiere atender a diversas áreas, planificar nuestras acciones y en muchos casos estar dispuestos a iterar.
Para qué nuestras probabilidades de éxito se magnifiquen, he preparado un checklist de elementos a los que atender en nuestra planificación.
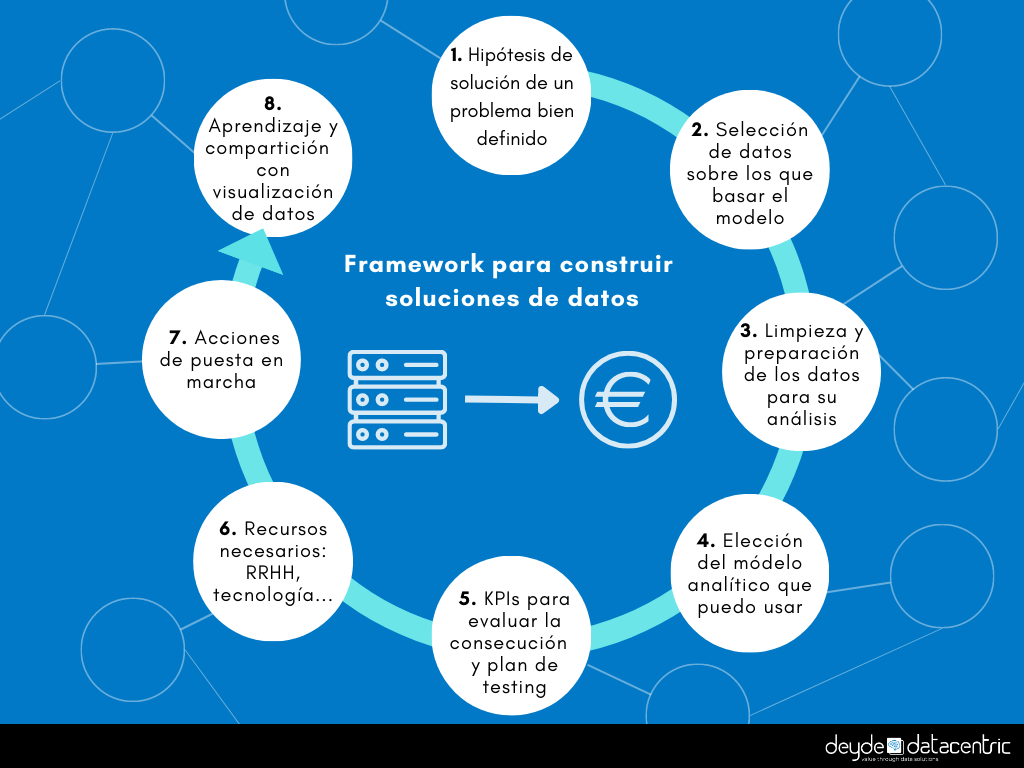
Pasos para implantar soluciones data driven orientadas a negocio:
1. Hipótesis de solución de un problema bien definido.
A la hora de elegir un problema es importante escoger problemas de negocio concretos y de alto impacto, con aliados de negocio afectados, y donde se puede demostrar un retorno de la inversión rápido. Es decir, es importante buscar victorias rápidas, quick wins! Pues se va a necesitar la colaboración y datos de unidades de negocio… y en las empresas hay mucha tendencia a no compartir datos.
Por ejemplo, mi problema puede ser no tener una visión unificada de mis clientes y como solución plantear la implantación de un CRM. Pero eso va a tener mucho desgaste de implantación, cambios culturales y tardaré probablemente más de 2 años hasta poder empezar a recoger beneficios. Es preferible empezar con problemáticas más concretas: reducir el churn, mejorar la respuesta de mis campañas de telemarketing o un modelo de mejora de las predicciones de demanda, etc. Y a partir de ahí conseguir medallas pronto antes de atreverme con problemáticas más complejas ya con aliados.
El problema debe estar bien definido. Esto es, identificar quién tiene el problema (unidades, departamento, clientes), y una evaluación de su impacto. Causas del problema e hipótesis de solución con datos.
Si mi objetivo es mejorar la predicción de demanda de equipos de aire acondicionado, pues valoro si con un modelo de datos puedo acertar en cuanto el mercado me va a demandar para evitar stocks y quedarme corto en ventas o largo en producto. En mi evaluación, diré que con mi modelo puedo reducir mis costes por bajar mis stocks o vender más en periodos de éxito por no quedarme sin stocks de productos de gran demanda temporal. Y mucho mejor si estos objetivos los puedo cifrar, p. ej. reducción de stock en un 20%.
2. Selección de datos que me ayudarían a en mi modelo.
En este paso analizaremos qué datos necesitamos para que nuestro modelo funcione. Para ello, debo hacer un mapeo de datos necesarios para nuestra solución, diferenciando entre si esos datos están en mi organización (internos), en el mercado (externos) y si son fácilmente tratables o no. Por ejemplo, hoy por hoy videos, logs o fotografía se pueden transformar en datos pero con un gran esfuerzo de tratamiento.
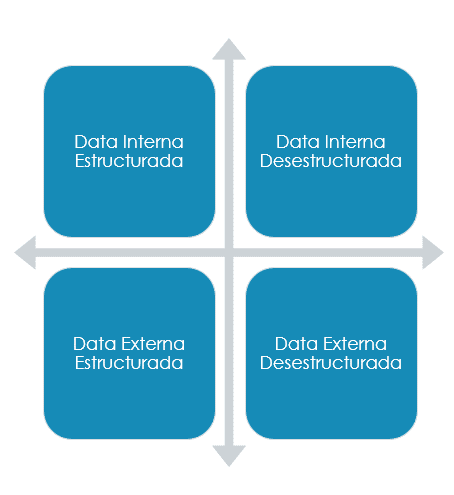
La información interna es la más fácil y barata. Por eso debemos empezar analizando qué fuentes de datos hay en mi empresa, quién los tiene y cómo se usan esos datos actualmente. Requiere preguntar mucho a las distintas unidades de negocio (IT, Finanzas, marketing…).
Seguramente con solo nuestros datos no nos llegue, sobre todo cuando buscamos respuestas de mercado y no solo de nuestros clientes. Gran parte de esta información que necesitemos pueden ser datos abiertos. Empresas como Deyde DataCentric os pueden ayudar a complementar y ofreceros todo un catálogo de datos completos. En el ejemplo de la predicción de demanda de equipos de aire acondicionado, datos como ventas históricas por fechas, calendarios de vacaciones, datos catastrales, datos de otros proveedores de la cadena de suministro y por supuestos datos meteorológicos nos podrían ayudar en nuestro modelo.
3. Limpieza y preparación de los datos para su análisis
Un tema importante son los procesos de calidad de datos para limpiar, validar y relacionar los distintos datasets. Pues con malos datos las respuestas de cualquier modelo serán erróneas.
En muchos casos en esta parte se va gran muchos de nuestros esfuerzos. En concreto más del 50% del tiempo de media. Por ello contar con soluciones profesionales que te permitan reducir tus esfuerzos como la nuestra de MyDataQ.
4. Elección del módelo analítico que puedo usar.
Según si lo que se quiere es dar respuesta a lo que ha pasado o predecir el futuro, la complejidad del módelo y su facilidad de aplicación se complicara.
Los data scientists y analistas te aconsejarán sobre el modelo estadístico o algoritmo más optimo.
En cualquier caso, en mi opinión no conviene enamorarse de “hypes”. No es obligado usar modelos sofisticados como Redes neuronales, gradial boosting, random forest. A veces es mejor es usar modelos estadísticos más sencillos. Es mejor un modelo sencillo que aporte una explicación de qué ocurre o me permita mejorar mi situación actual, que una caja negra que nos predice el futuro pero sin ningún entendimiento de que en se basa.
5. KPIs para evaluar la consecución de nuestras hipótesis y plan de testing.
Necesitaré métricas para evaluar la consecución de nuestras hipótesis. KPIs qué nos respondan a las hipótesis planteadas para saber cómo vamos. Ojo, partimos hipótesis a contrastar, hay que estar preparado para iterar. Pues puede funcionar o no, pero a lo mejor también descubrimos nuevos beneficios inesperados.
Siempre hay una oportunidad de testar. Ya sean test A/B o miltivariantes, e idealmente hacerlo siempre contra un grupo de control.
6. Recursos necesarios: RRHH, tecnología…
En mi planificación debe constar una dotación de recursos. En la parte de equipos, debemos identificar si no tenemos equipos preparados para interpretar data sets complejos, con lo cual en algunos casos se hace necesaria la contratación de personal competente en el análisis estadístico y matemático de datos. En otros casos se necesitará la ayuda de empresas externas que nos ayuden en la dirección de estos proyectos de análisis de datos o en la ejecución de trabajos específicos.
Con todo el modelo de datos definido en los puntos anteriores debemos identificar la solución tecnológica que permita correr a nuestro modelo sin problemas. Idealmente si podemos reusar una tecnología que ya tenemos en la casa mejor. Sino, seleccionar una tecnología que sea integrable con lo que tenemos vía API.
De todos modos, como recomendación general no nos dejemos deslumbrar por funcionalidades mágicas. La tecnología de base de datos debe ser un medio y no un fin. Es mejor un Excel con buenos datos y procesos que no una plataforma potentísima con datos no coherentes. Es mejor un modelo de analítica de datos con datos completos y veraces, que no cualquier modelo complicadísimo con datos erróneos.
Es decir, el proceso debe empezar por un caso bien definido de negocio, después seleccionar los algoritmos analíticos a aplicar y sólo al final ver qué soporte tecnológico se debe desarrollar.
7. Planificación de acciones para asegurar su puesta en marcha, monitorización e integración con las soluciones de la empresa.
Ahora es momento de llevar a la vida a nuestra solución. Se deben definir las acciones para que esto ocurra y estas deben estar lideradas por nosotros mismos para asegurar que nuestra solución se usa por las unidades de negocio que deben hacerlo. Pues sino se corre el peligro de que la misma se quede olvidada en un cajón.
También deberemos asegurar que la solución se integra bien con los sistemas existentes y monitorizar la solución una vez que está en producción para detectar y solucionar posibles problemas.
8. Medición, aprendizaje y compartición de lo aprendido.
Por último, todo lo que hayamos hecho lo debemos medir para ver si funciona o no y llegará el momento de sacar conclusiones y compartir los resultados y aprendizajes con todas las áreas relacionadas Marketing, IT o experiencia de clientes.
Espero que esta metodología te ayude en el éxito de tus proyectos. Si lo deseas también puede ver el video.

")











