
Los motores de recomendación web son herramientas que proporcionan sugerencias de elementos que pueden interesar a un gran número de usuarios, por ello son el enlace que permite unir tecnología y ecommerce. Permiten a los desarrolladores de algoritmos predecir si a los consumidores les gustará, o no, una serie de productos ofrecidos. A su vez, es una herramienta de consumo, ya que no sólo el producto que han marcado para la búsqueda, además les ofrece varias alternativas de productos que pueden despertar su interés.
Los motores de recomendación buscan principalmente ser relevantes e interesantes para los usuarios, novedosos o creativos, sorprendentes y además buscan la diversidad de productos. Consiguiendo con ello uno de los principales objetivos de las empresas, fidelizar el mayor número de consumidores. El incremento de la cantidad de datos libres y la aparición de nuevas herramientas Open Source, incentivan la creación de los motores de recomendación en diferentes sectores, siendo capaces de ofrecer recomendaciones cada vez más convincentes.
Existen diferentes algoritmos en función de la recomendación que se requiera por el negocio. Debemos ser capaces de diferenciar si nos encontramos ante una “estrategia de predicción del problema”, donde se establece una clasificación con los valores obtenidos de la combinación usuario-producto, o si, por el contrario, podemos encontrarnos con una “estrategia de ranking del problema”, donde se establece una clasificación de preferencia.
En primer lugar, debemos conocer el modelo denominado “Collaborative Filtering Methods”, cuya principal fuente de datos son las preferencias (ratings), aportadas por los diferentes usuarios, centrando su objetivo en el uso de las mismas como estrategia de recomendación. La creación de “matrices de utilidad” con los diferentes productos y especificaciones de usuarios facilita a las empresas la localización de missing values en algunos de sus ratings, y con ello las posibles soluciones que se debieran tomar ante dicha ausencia de valores, ya que el objetivo principal del recomendador sería predecir aquellos valores donde los usuarios no han mostrado su preferencia. Aquí podemos diferenciar:
- “Memory based methods” o “Neighborhoodbases Collaborative Filtering Algorithms”, donde las calificaciones de combinaciones usuario-producto son establecidas en base a sus vecinos. Podemos entenderlos a su vez de dos formas diferentes: centrando nuestro objetivo en un usuario donde se obtienen calificaciones vacías en determinadas categorías , pero que a su vez pertenece a un grupo de usuarios con gustos similares, por lo que su valor será cubierto con las calificaciones de usuarios semejantes (User Based Collaborative Filtering) o centrarnos en el producto para el cual el usuario ha dejado la calificación vacía, determinando primero el grupo de productos que muestran similitud con nuestro objetivo, donde el usuario previamente sí que puso sus puntuaciones, las cuales usaremos para determinar, si nuestro objetivo será atractivo para dicho usuario (Item-based Collaborative Filtering).
- “Model-based methods”, basados en métodos de Machine Learning y Data Mining para los modelos de predicción. Son aquellos casos donde el modelo está parametrizado, los parámetros aprenden dentro de un framework optimizado, como, por ejemplo, los árboles de decisión o modelos de factores latentes.
Los algoritmos de la familia Collaborative Filtering están estrechamente relacionados con los modelos de regresión. Aquí la variable dependiente puede considerarse como un atributo de los valores perdidos mencionados previamente. Esta relación existente entre modelos de regresión y filtros colaborativos es importante dado que muchos principios de clasificación y métodos de modelos de regresión pueden generalizarse a sistemas de recomendación.
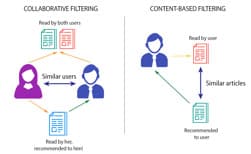
Como hemos comentado previamente cuando se trabaja con la información que se obtiene de los atributos de usuarios y productos como perfiles o palabras clave podemos hablar de otros sistemas de recomendación conocidos como “Content-Based Recommender Systems”. Las calificaciones y el comportamiento de compra de los usuarios se combinan con la información de contenido disponible en los artículos, sus descripciones, que están etiquetadas con calificaciones, y son utilizados como datos de entrenamiento para crear una clasificación específica del usuario o resolver problemas mediante modelado de regresión, prediciendo con ello si a la persona correspondiente le gustará un artículo no valorado o el comportamiento de compra es desconocido.
La familia de algoritmos Knowledge-Based Recommender son sistemas de recomendación basados en el conocimiento, particularmente útiles en el contexto de elementos que no se compran muy a menudo y, por tanto, pueden no estar disponibles valoraciones suficientes para el proceso de recomendación, siendo difícil la obtención de un número suficiente de valoraciones para una situación específica del elemento en cuestión. En estos casos el proceso de recomendación se realiza sobre la base de las similitudes entre requisitos del cliente y
descripciones de los elementos, o en la restricción del uso de requerimientos que especifican los usuarios.
Por último, los sistemas de recomendación híbridos y basados en conjuntos (“Hybrid and Ensemble-Based Recommender Systems”), están estrechamente relacionados con el campo del análisis de conjuntos, en el que, los algoritmos se combinan para crear un modelo más robusto mediante el uso de múltiples tipos de aprendizaje automático. Pueden combinar no solo la potencia de múltiples fuentes de datos, sino que también pueden mejorar la eficacia de una clase particular de sistemas de recomendación combinando múltiples modelos.
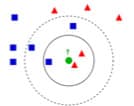
Para concluir podemos mencionar algunos ejemplos de algoritmos utilizados en estos sistemas de recomendación tales como Nearest Neighborhood algorithm (k-NN), donde la idea es predecir una clasificación basada en los k Nearest Neighborhoods sobre el producto que queremos clasificar. Por otro lado, podemos introducir el algoritmo Slope One, calificado como la forma más simple de Item-Bases Algorithms basados en ratings. El algoritmo se basa en la media de las diferencias entre usuarios que establecieron su rating en los mismos productos que queremos predecir.














