Hace unos días publicamos en Big Data Magazine un artículo en el que se hablabamos sobre algunos data sets gratuitos. Twitter es otra fuente de colección de datos que podemos utilizar de manera gratuita.
Os vamos a contar los pasos que debeís seguir para hacer vuestro propio analisis de datos en Twitter.
El primer paso es descargar los datos de Twitter, para eso hay varias opciones:
- Obtenerlos de la API pública de Twitter.
- Encontrar un conjunto de datos de Twitter existente.
- Compra en Twitter.
- Acceder o comprar desde un proveedor de servicios de Twitter.
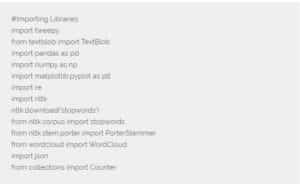
Nosotros vamos a utilizar una herramienta para la recuperación de la API pública de Twitter. Por eso, el primer paso es descargar estas bibliotecas ‘tweepy’, ‘textblob‘ y ‘wordcloud‘ usando ‘pip installtweepy‘, ‘pip installtextblob‘ y ‘pipinstalar wordcloud‘.
Descargar los datos de Twitter
Ahora procederemos a descargar los datos de Twitter, para ello utilizaremos la API «tweepy» donde debes crearte una cuenta con Twitter Developer. Después, de crear la cuenta eliges la opción «Comenzar» y vas a la opción «Crear una aplicación». Obtendrás las credencias requereridas.

Puede elegir la palabra clave aquí y el número máximo de tweets que se descargarán a través de la API de tweepy.
#Defining Search keyword and number of tweets and searching tweets
query = 'lockdown'
max_tweets = 2000
searched_tweets = [status for status in tweepy.Cursor(api.search, q=query).items(max_tweets)]Análisis
#Sentiment Analysis Report #Finding sentiment analysis (+ve, -ve and neutral) pos = 0 neg = 0 neu = 0 for tweet in searched_tweets: analysis = TextBlob(tweet.text) if analysis.sentiment[0]>0: pos = pos +1 elif analysis.sentiment[0]<0: neg = neg + 1 else: neu = neu + 1 print("Total Positive = ", pos) print("Total Negative = ", neg) print("Total Neutral = ", neu) #Plotting sentiments labels = 'Positive', 'Negative', 'Neutral' sizes = [257, 223, 520] colors = ['gold', 'yellowgreen', 'lightcoral'] explode = (0.1, 0, 0) # explode 1st slice plt.pie(sizes, explode=explode, labels=labels, colors=colors, autopct='%1.1f%%', shadow=True, startangle=140) plt.axis('equal') plt.show()

Aquí, crearemos una gráfica con todos los datos de tweets que hemos descargado. Más adelante, todos los datos procesados se guardarán en un archivo CSV en el sistema local. De esta manera, podemos utilizar estos datos de tweets para otros propósitos.
Creación del marco de datos y guardado en archivo CSV

Limpieza de textos de Tweet mediante operaciones de PNL
Como estamos listos ahora con el conjunto de datos de tweets, analizaremos nuestro conjunto de datos y limpiaremos estos datos en los siguientes segmentos.

Aquí, mientras tenemos ya listos los datos de tweets porque los hemos limpiado, realizaremos operaciones de PNL en los textos de tweets. Eliminaremos también la información que no es necesaria como retweets, hipertextos, etc.
#Cleaning Tweets
corpus = []
for i in range(0, 1000):
tweet = re.sub('[^a-zA-Z0-9]', ' ', tweet_dataset['text'][i])
tweet = tweet.lower()
tweet = re.sub('rt', '', tweet)
tweet = re.sub('http', '', tweet)
tweet = re.sub('https', '', tweet)
tweet = tweet.split()
ps = PorterStemmer()
tweet = [ps.stem(word) for word in tweet if not word in set(stopwords.words('english'))]
tweet = ' '.join(tweet)
corpus.append(tweet)Después de realizar las operaciones de NLP, podemos visualizar las palabras más frecuentes en los tweets a través de la Word Cloud.
Visualizar las palabras más frecuentes
#Visualization #Word Cloud all_words = ' '.join([text for text in corpus]) wordcloud = WordCloud(width=800, height=500, random_state=21, max_font_size=110).generate(all_words) plt.figure(figsize=(10, 7)) plt.imshow(wordcloud, interpolation="bilinear") plt.axis('off') plt.show()













