
Las compañías Data Driven y el procesado y almacenamiento masivo de datos son tendencia en los últimos años. La toma de decisiones basadas en datos es un mantra en la mayoría, si no todas, las juntas directivas de grandes empresas. La nueva misión de la transformación digital no pasa tanto por integrar nuevas tecnologías en los procesos de nuestras compañías como por recabar grandes cantidades de datos y hacer “algo” con ellos. ¿Qué podemos hacer con ellos? Eso queda para otro artículo.
En este artículo nos queremos centrar en una evidencia que nos ha dejado la experiencia con los datos del COVID 19, y es que no solo es importante recoger datos, si no saber para qué queremos esos datos. La forma y el formato en que se recogen y almacenan estos datos es casi tan importante como el dato en sí. Este “descuido” se produce en muchos otros entornos -incluidas grandes empresas que invierten grandes presupuestos- donde se recogen datos muy variados y se almacenan “por si acaso”, dejando para más adelante el pensar para qué se utilizarán. Podríamos pensar que cuantos más datos mejor, ¿no?
Lo importante: la calidad del dato
Sobre el papel, es cierto que cuantos más datos tengamos más probable es que dispongamos de las variables que necesitamos para resolver los problemas que se nos planteen en el futuro. Sin embargo, tanto al realizar analítica pura como al aplicar técnicas predictivas, la calidad del dato que se utiliza es fundamental. Incluso aplicando técnicas que requieren grandes volumetrías para identificar patrones relevantes, de nada sirve si esos datos están sesgados o son erróneos.
Desde el inicio de la pandemia, en España hemos padecido ese problema: los datos que reportaban las instituciones generalmente estaban retrasados, se actualizaban a posteriori provocando modificaciones en toda la serie o, directamente, se cambiaba sobre la marcha la manera de medir los valores. Esto deriva en que las decisiones que se toman para abordar el problema, teóricamente informadas, muchas veces no son las mejores porque se parte de premisas incorrectas.
Problemas similares surgen cuando en grandes empresas se procesan y analizan solo parte de los datos que se tienen -generalmente estructurados en bases de datos-, dejando de lado muchos otros datos -bien porque no se dispone de ellos de manera estructurada o porque el departamento en cuestión no los disponibiliza-. En estos casos, los análisis que se realizan o los modelos que se construyen, no tienen visibilidad sobre toda la realidad, sino sólo sobre un fragmento. Esto tiene como consecuencia que las decisiones que se toman se consideran informadas pero en realidad no lo son.
Partiendo de datos erróneos, las consecuencias pueden ser desastrosas, tanto que, a veces, es mejor tomar una decisión basada en la intuición que basada en una realidad que no existe. El mantra del que hablábamos al inicio de ‘tomar decisiones basadas en datos’ queda destruido en un instante por la desinformación que provoca el defecto de calidad del dato.
Solución: la cultura del dato
Para atajar este tipo de problemas, más allá de soluciones concretas según cada caso, es importante que en nuestra organización exista una buena cultura del dato. Este concepto de “cultura del dato”, que todo el mundo parece buscar pero pocos encuentran, no deja de ser una forma de hacer las cosas en la que todos los datos posibles se recolectan y distribuyen de manera proactiva.
Parece, sin embargo, que volvemos al mismo problema: recoger datos sin tener muy claro el objetivo.
En general, todos los datos que recogemos queremos utilizarlos, como mínimo, para poder analizarlos y generar conocimiento a partir ellos. Para conseguir este objetivo -y también para ser capaces de implantar una buena cultura del dato en nuestra organización- es importante cumplamos varias premisas:
- Todos los agentes de nuestra organización deben estar alineados e implicados con esta cultura. Como toda forma de trabajo, para que funcione correctamente todo el mundo tiene que estar alineada con ella. No sirve de nada recabar muchos datos en unas áreas si otras no van a proporcionar datos que pueden enriquecer o contrastar los primeros.
- Debe existir una definición común de conceptos. Los conceptos deben significar lo mismo para todos los sectores de nuestra organización, de manera que si recogemos ciertos datos en diferentes departamentos no tengan interpretaciones distintas.
Ambas premisas hemos podido ver cómo han sido claves en la gestión del Covid-19 justo por lo contrario de lo que deberían, por no haberse cumplido, y han desembocado en la incapacidad de tomar decisiones en base a los datos: con una constante desalineación entre los distintos agentes implicados y, desde el inicio, sin existencia de una definición común de los datos a registrar.
Adicionalmente, se deben acompañar de ciertas acciones concretas que son más difíciles de alcanzar:
- Las métricas deben tener significancia universal. Esto quiere decir que una métrica definida debe mantener su significado siempre. Si otro área recoge una métrica similar o se ve necesario modificar su significado, no se puede sobreescribir esa medida, se debe generar una nueva. Durante esta pandemia, por ejemplo, ha variado la forma de medir los nuevos casos. A mitad de la serie se modificaron los criterios para contar enfermos por lo que, de un día para otro, pasamos a tener menos enfermos, rompiéndose la serie. Otro ejemplo durante esta pandemia es que cada comunidad autónoma, incluso cuando había un método común, contabilizaba los casos en franjas temporales diferentes: atendiendo a cuando se notificó o a cuando se inició el contagio.
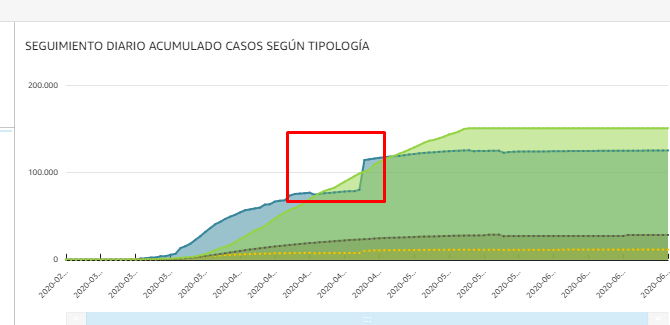
- Los datos deben disponibilizarse con la misma frecuencia y de manera rápida. Tener datos que tardan mucho en ser accesibles o que se disponibilizan de manera errática -a veces diariamente, a veces semanalmente- hace que la explotación sea muy complicada. En muchas ocasiones incluso puede tener un coste de oportunidad alto ya que los datos caducan y no son útiles.
- Toda la información debe disponibilizarse de manera estandarizada y explotable por herramientas de analítica. Este último punto quizás sea el más sutil de todos. No es útil tener grandes cantidades de datos disponibles en formatos no explotables. Por ejemplo, el Ministerio de Sanidad disponibiliza los datos diarios en formato PDF, que hace muy compleja la extracción de manera automatizada y, por tanto, hacer análisis avanzados. Implica que un ser humano debe extraer los datos manualmente de una tabla de texto, algo que con volumetrías altas es insostenible.

El objetivo de ser Data Driven es muy atractivo, pero también implica hacer las cosas bien desde un inicio y de manera extensiva a toda la organización. El uso de los datos en la gestión de la pandemia ha hecho muy evidente que abordar con desconocimiento y sin las buenas prácticas necesarias proyectos de este tipo, pueden convertir el valor del dato en un riesgo para la toma de decisiones.













