
Artículo de David Purón, CEO de Barbara.

A medida que el mercado se mueve de pruebas de concepto en el Edge a grandes despliegues multi aplicación que requieren de escalabilidad, aparecen diferentes alternativas tecnológicas y se requiere tomar decisiones.
En este artículo te contamos consideraciones clave para abordar un proyecto de Edge Computing maximizando las oportunidades de éxito en el futuro.
El Edge Computing se está convirtiendo en una tecnología clave para la digitalización de entornos y procesos industriales. La capacidad de ejecutar aplicaciones digitales cerca de los procesos productivos habilita múltiples casos de uso como la monitorización remota en tiempo real, el mantenimiento predictivo, la optimización del rendimiento de procesos, o la creación de nuevos modelos de negocio basados en intercambio de información.
Sin embargo, muchas empresas todavía encuentran retos en la introducción del Edge Computing en sus arquitecturas IT/OT.
A medida que el mercado se mueve de pruebas de concepto en el Edge a grandes despliegues multi aplicación que requieren de escalabilidad, aparecen diferentes alternativas tecnológicas y se requiere tomar decisiones.
El mundo industrial no es tolerante a fallos, y una mala decisión puede suponer el fracaso de esta implantación de tecnología. En este artículo te contamos consideraciones clave para abordar un proyecto de Edge Computing maximizando las oportunidades de éxito en el futuro.
Las bases de un proyecto de Edge Computing exitoso
El Equipo Humano, la base de todo. La Figura creciente del CDO
El reciente estudio de Stratus sobre las tendencias en el Edge muestra la falta de conocimiento general sobre el Edge, y más específico sobre IoT ( Internet of Things), como las grandes barreras a los despliegues coporativos de Edge Computing.
A menudo muchas compañías eligen a sus directores de sistemas (CIO) u operaciones (COO) liderando los despliegues de Edge Computing. En nuestra opinión, esto no es óptimo, ya que esto les desvía de sus objetivos más tradicionales, y además carecen de experiencia al respecto. Idealmente, debería ser el Chief Data Officer (CDO) de la organización el que lidere este despliegue.
El Chief Data Officer es el máximo responsable de la gestión de los datos como un activo en toda la empresa. Su gran objetivo es la reducción de costes o incremento de ingresos a través del procesamiento avanzado o comercialización de los datos provenientes de los procesos productivos. Este perfil, normalmente con un mix de conocimientos matemático-científicos y de verticales del mercado en el que opera la compañía, entiende muy bien los beneficios que el Edge trae en materias como la velocidad y la escalabilidad en el tratamiento de datos,o la seguridad de los mismos. Pero mucho más importante que eso, el Edge impacta directamente en los resultados y objetivos del CDO, y por tanto su impulso será natural.
Por eso, nuestra primera recomendación a cualquier empresa que desee implementar Edge Computing es contratar un CDO y poner a su disposición un equipo con los perfiles necesarios para llevarlo a cabo, tales como científicos de datos, ingenieros de sistemas y expertos en ciberseguridad.
Las fases del Edge Computing, divide y vencerás

El despliegue de Edge Computing, liderado por el CDO, debe realizarse faseado en un proceso ágil pero estructurado. Cada fase tiene sus objetivos e indicadores de éxito diferenciados. De no hacerlo, podemos entrar en una espiral de errores interconectados que terminen con un sistema inestable e ineficiente.
Las cuatro fases que recomendamos desde Barbara IoT se describen a continuación. En ocasiones surge la pregunta de cuán largo es este proceso: con el equipo y los productos adecuados, podemos estar hablando de un proceso de no más de tres meses, pero cuyos beneficios quedarán en la organización para toda la vida.
Fase 1: selección del caso de uso
Una implementación exitosa comienza por comprender exactamente cuál es su objetivo y qué se espera lograr. Antes de contactar al primer proveedor, instalar el primer equipo, o escribir la primera línea de código, hay que ser capaz de seleccionar una “killer application” que sirva como punta de lanza en el despliegue de Edge Computing. Para ello, lo mejor es realizar un análisis para identificar aquellos procesos que cumplan el máximo número de las siguientes condiciones:
- No están optimizados, existe una carga importante de toma de decisiones con poca información
- Manejan una gran cantidad de datos
- La seguridad de los datos es importante
- Requieren de una toma de decisiones rápida, cercana al tiempo real
- Contienen activos distribuidos y su conectividad puede ser un reto
Realizando una revisión de los procesos críticos de la empresa y clasificándolos en una matriz con estos cinco ejes, podemos encontrar el proceso o procesos cuya mayor puntuación implica que es un candidato indiscutible para beneficiarse de la computación en el extremo.
Fase 2: recolección de datos
Una vez seleccionado el caso de uso, se debe comenzar una fase de recolección, limpiado, etiquetado y almacenado de los datos que maneja el proceso. Para ello, se desplegarán los primeros Nodos Edge y mediante el uso de Conectores Software, podemos recoger datos de sensores, actuadores, equipos industriales y servidores internos o externos.
Los datos recogidos pueden limpiarse para eliminar inconsistencias y etiquetarse para mejorar su posterior procesamiento. En ocasiones, se puede incluir en esta fase un tratamiento sencillo de datos como la generación de alarmas ante datos anómalos, o la generación de sencillos reportes de indicadores sobre el proceso. Este no es el fin último del despliegue, pero ayudará a depurar cualquier error y llegar a mejores conclusiones.
Fase 3: entrenamiento de los modelos
Utilizando los datos que están siendo recolectados de manera continua, comienza la fase de entrenamiento de los modelos. En esta fase hay aspectos claves como la estandarización, la correcta selección de herramientas, o el diseño para lograr interoperabilidad de modelos, que describe perfectamente el artículo “how to scale AI” de Harvard Business Review. En este proceso liderado por científicos de datos, las plataformas de Edge Computing ayudan con las funcionalidades relacionadas con MLOps, que permiten generar, probar y ejecutar modelos de manera ágil y segura.
Fase 4: despliegue, operación y gobierno de la IA distribuida
Una vez los científicos de datos deciden que los modelos están suficientemente entrenados, entran en juego los sistemas que, como el Edge Orchestrator de Barbara permiten enviar, arrancar, monitorizar, parar, o actualizar aplicaciones y modelos a miles de Nodos Edge distribuidos. Dependiendo del volumen del despliegue, puede ser interesante hacer “roll-outs” progresivos por localizaciones hasta cubrir todo el territorio. En este punto y una vez las aplicaciones distribuidas estén controlando el proceso con los modelos entrenados, habremos alcanzado el máximo potencial del Edge Computing y podremos contrastar las mejoras obtenidas con las expectativas definidas en la primera fase del proceso.
Elegir el tipo correcto de Edge Computing para cada proyecto
Edge Computing es un tipo de arquitectura genérico, pero cuando se aplica a una industria o proyecto concreto es importante conocer sus diferentes variantes para poder aplicar aquella que más convenga.
Cada vez es más común diferenciar entre dos tipos de Edge: Thick Edge (Grueso) y Thin Edge (Fino) o también llamado Gateway Edge, que hacen referencia al lugar donde se realiza el procesamiento.
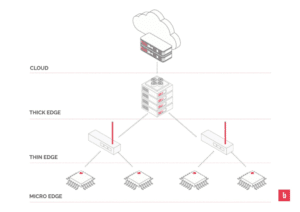
Thick Edge
Se denomina al procesamiento que se realiza en nodos, situados en la infraestructura del operador troncal de red, pero cercanos a los dispositivos del cliente. Esto, en una red celular móvil, puede ser la antena a la que conectan los dispositivos, o en una infraestructura de red fija puede ser un servidor situado en el centro de datos más cercano a nuestra localización.
Se denomina “Thick” (grueso) porque estos nodos suelen tener una alta capacidad de procesamiento, en primer lugar porque están situados en lugares donde el consumo eléctrico o el espacio no es un problema, y en segundo lugar porque al pretender al operador de red tiene que ser capaces de procesar datos de múltiples clientes finales. Cuando los operadores de telecomunicaciones hablan de Edge Computing, se refiere a este tipo de casuística.
Thin Edge o Gateway Edge
Implica que el procesamiento se realiza en nodos propiedad del cliente final, situados en su red local, y por tanto todavía más cerca de sus dispositivos. El adjetivo “Thin” (fino) es en este caso adecuado ya que estos nodos suelen estar más limitados en capacidad de procesamiento y consumen menos recursos que los dispositivos del Thick Edge.
Si bien no se puede trazar una línea perfecta entre Thick Edge y Thin Edge ya que hay casos donde ambos modelos podrían funcionar, es interesante entender sus diferencias desde algunos puntos de vista para poder elegir aquel que más se ajuste a nuestro proyecto:
- Desde el punto de vista de la latencia, Thin Edge puede procesar datos a mucha mayor velocidad que el Thick Edge. La gran promesa de los operadores de red para eliminar latencias son las redes 5G, pero incluso en el nuevo estándar es complicado bajar en la práctica de latencias menores a los 20ms, cuando si el procesado se realiza en la red local podemos llegar al “casi tiempo real” con latencias cercanas a 1ms.
- Si hablamos de seguridad y privacidad, el Thin Edge permite preservar si cabe más la privacidad y seguridad de los datos, ya que estos no abandonan la red local del cliente, como ocurre en el Thick Edge que requiere llevar los datos un paso más allá hasta la infraestructura del operador local que está fuera de nuestro control.
- En el caso del coste, un despliegue de Thin Edge suele requerir una inversión inicial mayor para la compra e instalación de Nodos, mientras que el Thick Edge al implicar nodos compartidos del operador de red, suele moverse con estructuras tipo “IaaS” (Infraestructure as a Service) con pagos por uso que no requieren inversión inicial.
- Por último, como ya hemos comentado anteriormente, los Nodos del Thick Edge pueden procesar un volumen mayor de datos por estar dotados de mayores recursos que los Nodos del Thin Edge.
Esto hace el Thin Edge mucho más adecuado para entornos que requieran latencias de respuesta rápidas, que se quieran aislar lo máximo posible del operador de red por seguridad o privacidad, y donde se disponga de presupuestos de inversión (CAPEX) para acometer los proyectos. Normalmente, esto coincide con entornos industriales de verticales como Energía, Agua, Infraestructuras.
El caso del Thick Edge es sin embargo más adecuado para aquellos sistemas donde la latencia no sea absolutamente crítica, que requieran procesar flujos de datos de ancho de banda significativo y tendentes a operar con costes operativos (OPEX) en lugar de inversión.
Industry at the Edge
¿Quieres saber más sobre proyectos de Edge Computing y conocer a las empresas que están desplegando inteligencia artificial en el Edge? Te esperamos en Industry at the EdgeEl 25 de Octubre, se celebra en Madrid, el evento más importante sobre Computación en el Edge con modelos de IA y ML en el que se presentarán proyectos pioneros en la implantación de inteligencia avanzada en distintos sectores industriales.
Industry at the Edge
Más de 17 empresas y 26 profesionales compartirán su visión y experiencia sobre cómo llevar a cabo la transformación digital con tecnologías disruptivas como la IA y ML en el Edge.
En este enlace encontrarás la agenda y sus protagonistas.




, la compañía de infraestructura de datos inteligente. (1)")








